今天同事使用scrapy遇到一个问题,报错如下:
Traceback (most recent call last):
File "/Library/Python/2.7/site-packages/scrapy/core/engine.py", line 111, in _next_request
request = next(slot.start_requests)
File "/Library/Python/2.7/site-packages/scrapy/spiders/__init__.py", line 70, in start_requests
yield self.make_requests_from_url(url)
File "/Library/Python/2.7/site-packages/scrapy/spiders/__init__.py", line 73, in make_requests_from_url
return Request(url, dont_filter=True)
File "/Library/Python/2.7/site-packages/scrapy/http/request/__init__.py", line 24, in __init__
self._set_url(url)
File "/Library/Python/2.7/site-packages/scrapy/http/request/__init__.py", line 59, in _set_url
raise ValueError('Missing scheme in request url: %s' % self._url)
ValueError: Missing scheme in request url: h
看到scrapy源码中抛出异常的这个代码:
def _set_url(self, url):
if isinstance(url, str):
self._url = escape_ajax(safe_url_string(url))
elif isinstance(url, six.text_type):
if self.encoding is None:
raise TypeError('Cannot convert unicode url - %s has no encoding' %
type(self).__name__)
self._set_url(url.encode(self.encoding))
else:
raise TypeError('Request url must be str or unicode, got %s:' % type(url).__name__)
if ':' not in self._url:
raise ValueError('Missing scheme in request url: %s' % self._url)
按说URL中是包含冒号的,怎么会报这个错,而且报错提示是
ValueError: Missing scheme in request url: h
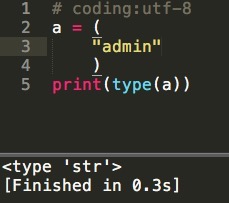
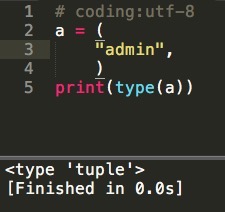
看到这个想起http://****,http中的h被当成了一个域名,原因是这样的:在spider文件中,start_url是个tuple,里面写的网址如果不止一个就不会出错,但是如果只有一个网址,如果你漏写了逗号,Python就不会认为它是个tuple,看下图: